A DHT is a key-value structure that is spread across a wide-area network like the Internet. You feed a key into the DHT and it will return a value. It is used in distributed + peer-to-peer systems as a rudimentary data-store.
Before DHT existed many "distributed" networks actually used centralized servers (or a set of central servers) that acted as authorities on the network. This is how Napster operated for its brief life and this centralized architecture likely led to its ass getting clapped by the RIAA in 1999. Interestingly Soulseek still operates with a set of centralized servers and I'm honestly not sure how it has avoided a similar fate. I do know that Soulseek censors certain queries on these central servers like "Bob Dylan" or "Beatles"; whether that is self-censorship or not is left to the imagination.
Many of the later distributed file-sharing networks used DHT to socialize new clients with other peers already on the network and to allow the discovery of files by network peers without a central server. The earliest example I can think of is Freenet (2000) and though technically Freenet did not use a proper DHT until later on in its development Freenet's earliest iterations used a lookup very similar to a DHT.
The better choice for creating a censorship-resistant network is to distribute the storage of look-up data from a central server outward to the peers on the network; not incurring a single point of failure is the biggest reason why DHTs are popular in decentralized systems. Instead of "phoning home" to the big server in the NSA server closet peers on the network use the DHT to socialize with new clients joining the network and to discover of files hosted by other network peers.
One way we could network with other peers is to simply flood the network with requests when any peer is looking for a certain file. This is how Gnutella operates and it is how Soulseek peers discover files too (after routing through the central server to relay its request to peers). Flooding like this creates an inscalable network however, as each new client added to the network graph causes the number of messages each peer has to send in order to flood the network completely to increase exponentially.
Kademlia DHTs
DHT fixes the issues created by flooding. Kademlia in particular is the flavor of DHT I know the best and so I will explain concepts using the Kademlia DHT, though the ideas are generally the same for any DHT structure.
Nodes in a Kademlia network are organized into a binary tree according to each node's unique node ID. Often this is a hash of some information that is unique to the node like its IP address + listening port. So you don't get rainbow-tabled out of existence normally a salt is added to this content before it is hashed.
The distance between two nodes in a vanilla Kademlia network is defined as the XOR of the node IDs. XOR is chosen partly because it is a transitive operation so that the distance from A to B is the same as the distance from B to A. This distance determines the k-bucket (below) into which any known peers are stored. Peers which are further away from a given node are also further away in the network's binary tree.
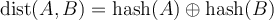
Storing Data in a Kademlia DHT
Any data that needs to be stored into the DHT is hashed using the same algorithm that is used to create node IDs. The data is stored at the nodes that have the smallest XOR-distance (are "closest") to the hash of the data. When any node needs to lookup that data in the DHT it queries its neighbor that is "closest" to the hash. If that neighbor doesn't have access to the data itself it will ask its own neighbors the same thing; queries propagate the binary tree this way until the data is found.
The data stored in the DHT here is arbitrary; it could be a file itself but
often it is information on where to acquire the file; either a "IP:port"
combination or another key to the DHT. Since you can hash any arbitrary data you
can store anything in this tree, and you can even mix and match the types of
data you are storing by appending a namespace to the key, e.g.
image:065474e2fe971c80aac049d6f7b978a0
Take this image of the protagonist of Mahoromatic, one of my favorite manga / anime.
I know its unique MD5 hash is f00370836e8f32c8f930af4b59163c04 and its IPFS
content identifier (CID) is QmX8CSdgWFdgACxY71GVJwgVB19Bn3An5zNnzH1Mj82ut2.
The CID is encoded with base58 (the same encoding as Bitcoin addresses) and
points to a Merkle DAG built from the small chunks of the file. Because this
file is quite small (137 KiB) it fits all into one block.
ipfs@gyw:~$ md5sum mahoro.jpeg f00370836e8f32c8f930af4b59163c04 mahoro.jpeg ipfs@gyw:~$ ipfs add -Q --only-hash mahoro.jpeg QmX8CSdgWFdgACxY71GVJwgVB19Bn3An5zNnzH1Mj82ut2
If I were to use the hash as the key into a DHT I could store the entire picture at this hash. For larger files this poor design however because I'd be storing large files on an arbitrary peer that probably doesn't want to host my file. What if I chose to hash an illegal file? Then your node would probably get raided by the fed while I was safe at home. For these reasons networks like Freenet chunk files before storing them in the DHT and may choose to encrypt chunks too, such that only peers with the decrypting key can read the chunks.
When files are chunked like this the hash of the whole file normally points to a Merkle DAG which can be walked to read the whole file. This is essentially how IPFS stores files; directories can be a little more complex. However because the file is so small it is stored entirely in the block which describes the DAG.
Interestingly this file was already existant on IPFS before I added it.
ipfs@gyw:~$ ipfs dag stat QmX8CSdgWFdgACxY71GVJwgVB19Bn3An5zNnzH1Mj82ut2 Size: 140270, NumBlocks: 1
By "adding" it to the network again I only cached the block temporarily on my client. When I upload this image to my VPS and consequently pin it on IPFS it will be available at least as long as my server keeps it pinned. Though the fact it was already available on IPFS means someone is likely pinning a (sub)set of Danbooru images already...
K-buckets
Nodes organize their neighbors into "k-buckets"; these represent a branch of the whole binary tree and each node needs to know at least one node in each k-bucket to be able to route a query to any node in the tree. K-bucket knowledge is normally acquired by a node when it joins the network but the contents of its k-buckets will change over time as nodes churn into and out of the network, since nodes will ping their neighbors to ensure they are still connected and responding.
Ideally a node in a DHT is geographically close to its neighboring nodes. When we define distance as an XOR however nodes may be close in XOR-distance but far away geographically. This is not something I think is addressed in Kademlia but in a more flexible DHT like Chord it may be possible to form neighbor-relationships instead that are close geographically.